Project Settings
Each project has its own set of settings, most of them initialized with a
value inherited from the Designer
Preferences. These settings are called Project Settings, and
are editable through the Project
Settings Editor.
The meaning of each property setting is described below. Each property is
listed in the same group as it is listed in the Project Settings Editor.
It's highly recommended you examine the various project settings right
after you have created a new project, as they control the behavior of the
various features of the designer when operating on various project elements.
A project setting overrides a preference with the same meaning.
This helps with a consistent designer behavior when a project file is shared
among team members: the project properties are stored inside the project
file, the designer preferences are stored locally on the user's computer.
Per setting group, reflected as a node in the left tree of the Project
Settings Editor, the settings are described in more detail below. To open
the Project Settings Editor, load an LLBLGen Pro project, and use the menu
option Project -> Settings, or right-click the Project node in
the Project Explorer and select Settings from the context menu.
This brings up the following dialog:
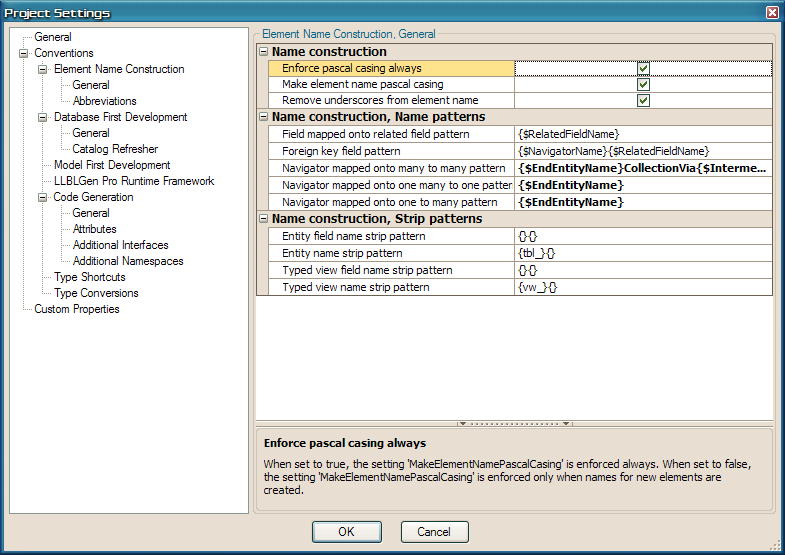
The Project Settings Editor
General
Designer behavior
- Additional task performer folder If specified, LLBLGen Pro will
look for taskperformer assemblies in this folder as well, besides the
default taskperformer folder. Specify the folder with full path or if
you want to make the path relative to the project location, specify the
path as a relative path. A relative path starts with '.' or with '..'
(without the quotes). If you don't want to use an additional folder,
leave it empty.
- Additional tasks folder If specified, LLBLGen Pro will look for
*.tasks/*.platform/*.presets files in this folder as well, besides the
default Tasks folder. Specify the folder with full path or if you want
to make the path relative to the project location, specify the path as a
relative path. A relative path starts with '.' or with '..' (without the
quotes). If you don't want to use an additional folder, leave it empty.
- Additional templates folder If specified, LLBLGen Pro will look
for templateGroups.config/*.language/*.templatebindings/*.frameworksettings
files in this folder as well, besides the default Templates folder and
the additional templates folder defined in the LLBLGen Pro preferences.
Specify the folder with full path or if you want to make the path
relative to the project location, specify the path as a relative path. A
relative path starts with '.' or with '..' (without the quotes). If you
don't want to use an additional folder, leave it empty.
- Additional type converter older If specified, LLBLGen Pro will
look for assemblies with TypeConverter classes in this folder as well as
.typeimports files, besides only in the default TypeConverterRootFolder
folder defined in the LLBLGen Pro config file. Specify the folder with
full path or if you want to make the path relative to the project
location, specify the path as a relative path. A relative path starts
with '.' or with '..' (without the quotes). If you don't want to use an
additional TypeConverter folder, leave it empty.
- Auto assign sequences to integer pks When set to true (default),
the designer will for every auto-mapping action try to assign a sequence
to every integer typed identifying field, if the identifying field is
the only field for the entity, it's not a foreign key field and not
inherited. If no sequence could be found and the target database
supports user sequences, a new sequence will be created, using
SequencePattern.
- Auto assign type converter to field mapping When set to true, the
Type Conversion Definitions in the project are searched for a matching
Type Converter for the mapping of a field and if found the Type
Converter is assigned automatically to the field's mapping. Used during
reverse engineering, relational model data refresh, forward mapping to
new fields and forward mapping to existing fields. Default is false.
- Group usage This setting controls how the grouping
functionality of the designer is used with respect to the generated
output: solely as visual grouping construct (default) (so all elements
in the entire project are seen as one project) or as separate projects
(one per group). If you choose to see groups as separate projects,
validation will verify that there are no ties between groups whatsoever
and will report errors if there are. If you choose to see groups as a
visual grouping construct only, validation will verify if there are
duplicate named elements among groups and will report errors if there
are.
- Target per entity edges require backing fk constraint. If true (default), the designer will require that
every inheritance edge between a subtype and a supertype in a hierachy
of type TargetPerEntity has a backing foreign key constraint in the
relational model data (if supertype and subtype are mapped both mapped
onto tables in the same catalog). Only set this to false in the
situation when you need to define a TPE hierarchy and can't add new
foreign key constraints.
- Use custom field ordering on new elements. False by default. If true, it will set the FieldIndexes
of the fields created through reverse engineering and when fields are
added to a new entity through model-first functionality. This setting
can help in a DB first scenario when ordinals on target tables have to
be used to guide field ordering, and when new entities are created in
the designer and fields have to have a given order from the start.
Miscellaneous
- Project creator. The name of the person who created this
project.
- Project name. The name of the project.
Validation / Relational model data adjustment
- Excludable orphaned element detected action The action to perform
when the system detects an 'orphaned' excludable relational model data
element (element which is not a mapping target). If the specified value
isn't applicable for the specific element, ExcludeFromProject is
used instead.
- Non excludable orphaned element detected action The action to
perform when the system detects an 'orphaned' non-excludable relational
model data element (element which is not a mapping target). If the
specified value isn't applicable for the specific element, RaiseError
is used instead.
Conventions: Element Name Construction, General
Name construction
- Enforce pascal casing always When set to true, the setting 'Make
element name pascal casing'
is enforced always. When set to false, the setting 'Make element
name pascal casing'
is enforced only when names for new elements are created.
- Make element name pascal casing When set to true, all names of
new entities, entity fields, typed views etc. will be properly PasCal
cased. This means that each character in the name is lowercased, except
the first character after each word boundary ('_' or ' ') and the first
character. All spaces are always removed. When set to false, the name is
left untouched, except for the first character, which will always be
UpperCase.
- Remove underscores from element name When set to true, all single
underscores in names of new entities, entity fields, typed views etc.
will be removed. When set to false, the name is left untouched.
Name construction, Name patterns
- Field mapped onto related field pattern The pattern which is used
to construct the names for Fields mapped onto a related field. Pattern
elements can be: {$RelatedEntityName} for the name of the related entity
which contains the mapped related field and {$RelatedFieldName} for the
name of the field in the related entity which is mapped by the field
mapped onto a related field. You can also specify any literal text. An
element can be mentioned more than once.
- Foreign key field pattern The pattern which is used to construct
the names for Foreign Key fields in entities. Pattern elements can be:
{$NavigatorName} for the navigator name mapped onto the relationship
used, {$RelatedFieldName} for the field referred to by the foreign key
field (the PK field) and {$RelatedEntityName} for the name of the
related entity (the PK side). You can also specify any literal text. An
element can be mentioned more than once.
- Navigator mapped onto many to many pattern The pattern which is
used to construct the names for Navigators mapped on m:n relationships.
Pattern elements can be: {$StartEntityName} for the name of the start
entity, {$EndEntityName} for the name of the end entity, {$IntermediateEntityName}
for the name of the intermediate entity, $P or $S suffix to entity name
macros to pluralize or singularize them (example: {$EndEntityName$P}),
{$StartEntityFieldNames} for all the names of the fields of the
relationship in start entity, {$EndEntityFieldNames} for all the names
of the fields of the relationship in the end entity and any literal
text. An element can be mentioned more than once.
- Navigator mapped onto one many to one pattern The pattern which is
used to construct the names for Navigators mapped on m:1 or 1:1
relationships. Pattern elements can be: {$StartEntityName} for the name
of the start entity, {$EndEntityName} for the name of the end entity, $P
or $S suffix to entity name macros to pluralize or singularize them
(example: {$EndEntityName$P}), {$StartEntityFieldNames} for all the
names of the fields of the relationship in start entity, {$EndEntityFieldNames}
for all the names of the fields of the relationship in the end entity
and any literal text. An element can be mentioned more than once.
- Navigator mapped onto one to many pattern The pattern which is used
to construct the names for Navigators mapped on 1:n relationships.
Pattern elements can be: {$StartEntityName} for the name of the start
entity, {$EndEntityName} for the name of the end entity, $P or $S suffix
to entity name macros to pluralize or singularize them (example: {$EndEntityName$P}),
{$StartEntityFieldNames} for all the names of the fields of the
relationship in start entity, {$EndEntityFieldNames} for all the names
of the fields of the relationship in the end entity and any literal
text. An element can be mentioned more than once.
Name construction, Strip patterns
- Entity field name strip pattern The pattern which contains two
sections, enclosed in {}, one for the prefixes and one for the suffixes.
Add prefixes and suffixes to strip off by separating them by a comma.
The first match is stripped. If the entity field's name is equal to a
prefix/suffix strip pattern, nothing is stripped off. Stripping is case
insensitive.
- Entity name strip pattern The pattern which contains two
sections, enclosed in {}, one for the prefixes and one for the suffixes.
Add prefixes and suffixes to strip off by separating them by a comma.
The first match is stripped. If the entity's name is equal to a
prefix/suffix strip pattern, nothing is stripped off. Stripping is case
insensitive. Example: prefix
strip pattern tbl_ and suffix strip pattern _dev will form the strip
pattern {tbl_}{_dev}.
- Stored proc name strip pattern The pattern which contains two
sections, enclosed in {}, one for the prefixes and one for the suffixes.
Add prefixes and suffixes to strip off by separating them by a comma.
The first match is stripped. If the stored procedure's name is equal to
a prefix/suffix strip pattern, nothing is stripped off. Stripping is
case insensitive. Example: prefix
strip patterns pr_ and sp_ and suffix strip pattern _dev will form the
strip pattern {pr_, sp_}{_dev}.
- Typed view field name strip pattern The pattern which contains two
sections, enclosed in {}, one for the prefixes and one for the suffixes.
Add prefixes and suffixes to strip off by separating them by a comma.
The first match is stripped. If the typed view field's name is equal to
a prefix/suffix strip pattern, nothing is stripped off. Stripping is
case insensitive.
- Typed view name strip pattern The pattern which contains two
sections, enclosed in {}, one for the prefixes and one for the suffixes.
Add prefixes and suffixes to strip off by separating them by a comma.
The first match is stripped. If the typed view's name is equal to a
prefix/suffix strip pattern, nothing is stripped off. Stripping is case
insensitive. Example: prefix
strip pattern vw_ and suffix strip pattern _dev will form the strip
pattern {vw_}{_dev}.
Conventions: Element Name Construction, Abbreviations
LLBLGen Pro supports the automatic conversion of abbreviation fragments in names into full name fragments using abbreviation-full word pairs defined per project. You can specify these
abbreviation-full word pairs in the 3rd tab of the Project Properties.
For example a field called 'Addr' or fields with 'Addr' in the name can be updated with 'Addr' being replaced with 'Address' so CustAddr will then become CustAddress, and if 'Cust' is also added to the abbreviations to become Customer, it will convert CustAddr into CustomerAddress. Abbreviations are stored inside the project file so everyone using the same
project file has the same abbreviations. They're simple Abbreviation - FullWord pairs
and don't use regular expression syntaxis. They're matched with fragments found during name processing. Fragments are elements separated by non-usable characters, space, underscore, a full word, or where an Uppercase/Lowercase change appears. So the string AaBb_CCC Ddd has 4 fragments: Aa, Bb, CCC and Ddd.
The following rules apply:
- Abbreviations are added per project, in the Project Properties
Editor, and should be inserted right after the project has been created and before the entities are added to the project.
- They're used during reverse engineering, when names have to be created for entities, typedviews and stored procedures, and fields for entities, typedviews
and for parameters for stored procedure calls
- The abbreviations are evaluated during name processing and before a FieldMappedOn*Pattern/NavigatorMappedOn*Pattern has been applied and also before casing rules have been applied.
- All abbreviations are case insensitive.
- Abbreviations can be used as well to specify specific casing. For example the abbreviation - full word pair: ID - ID will make sure that all ID fragments found won't be cased to Id, but will kept as ID.
It's also possible to export/import abbreviations to/from textfiles. These textfiles should have at each line the abbreviation and the full word separated by a TAB so example: addrTABAddressCRLF
Conventions: Database First Development, General
Reverse Engineering
- Auto add many to many relationships When set to true, the designer
will automatically add new m:n relationships it detects during the
reverse engineering process of entities from relational model data.
Default is false.
- Fk fields are named after target field When set to true (default),
the name of a foreign key field in an entity created through reverse
engineering, is created from the target field of the foreign key field.
When set to false, the Foreign key field pattern is used to construct the
name for the foreign key field.
- Retrieve db custom properties When set to true, all custom
property data of the database objects a new project object is based on
will be copied to the object's Custom Properties.
- Set group name after schema name When set to true (default), the
designer will automatically set the group name of new elements to the
name of the schema the target element is located in. If the target
database has a default schema name (e.g. 'dbo', the default schema
name is converted to the empty string for the group name. If the target
database doesn't use schemas, this setting is ignored.
Conventions: Database First Development, Catalog Refresher
Catalog Refresher
- Add new elements after refresh When set to true, any new entities, typed views and stored procedures
are added to the project automatically after a catalog refresh has been completed.
The value Default means the value in the preferences is used.
- Add new fields after refresh When set to true (default), any
newly found, unmapped field in an entity's target, which hasn't been
removed previously from the entity, is added as a new entity field to
the Entity automatically after a catalog refresh has been completed,
except if the entity is in a TargetPerEntityHierarchy hierarchy and not
the root of the hierarchy. If the entity is in a
TargetPerEntityHierarchy hierarchy and the new target field is not
nullable, it's added to the root entity only, if this setting is set to
true. The value Default means the value in the preferences is
used.
- Add new views as entities after refresh When set to true, for each
new view found in the catalog(s) a new entity will be added to the
project automatically, after a catalog refresh has been completed.
Default is false. This option is ignored if Add new elements after refresh has been set to false as well. The value Default means the value
in the preferences is used.
- Identifying fields follow db primary key constraints When set to
true (Default), all identifying fields in entities have to have a target
field which is also a primary key in the new relational model data after
refresh, or they'll be cleared from being identifying fields. When set
to false, identifying fields without a primary key field as target in
the new relational model data are left as-is and there aren't any fields
marked as identifying fields based on primary key fields found in the
new relational model data. The value Default means the value in
the preferences is used.
- Length precision scale follow db length precision scale When set to
true (Default), a model field / parameter will have its type parameters
max length, precision and scale synced with the target it is mapped on (ValueType
contained fields are not updated, as they can have more than one
target). When set to false, it will leave the model field / parameter
type information as-is, which could cause validation errors. The value
Default means the value in the preferences is used.
- Relationships follow db foreign key constraints When set to true
(Default), all normal relationships which are not marked as 'model-only' have to have a foreign key constraint in
the new relational model data after refresh, or they'll be removed. When
set to true, new relationships are created from newly found foreign key
constraints. When set to false, relationships without a foreign key
constraint in the new relational model data are left as-is and there
aren't any new relationships created from foreign key constraints found
in the new relational model data. The value Default means the
value in the preferences is used.
- Remove unmapped elements after refresh When set to true, any
element which doesn't have a mapping after a catalog refresh is removed
from the project. Default is false. The value Default means the
value in the preferences is used.
- Reset field order based on target order at refresh. This setting,
false by default, when true, resets all field indexes to the target
ordinal after a catalog refresh.
- Sync mapped element names after refresh When set to true, LLBLGen
Pro will rename any entity, navigator, typed view, entity field and
typed view field if the name of the element they're mapped on has
changed, for example a table field was renamed. Setting this option to
true can break your own code, so use this option with care. When
Sync renamed mapped element names after refresh is set to false, only
non-manually changed element names are synced, otherwise all element
names are synced. The value Default means the value in the
preferences is used.
- Sync renamed mapped element names after refresh When set to true
(default: false), LLBLGen Pro will sync manually renamed elements after
a refresh if Sync mapped element names after refresh is set to true and the
name of the element they're mapped on has changed. If
Sync mapped element names after refresh is set to false, this setting is
ignored. Multiple entities mapped onto the same target will all be
resynced in case of a target name change, so use this setting with care.
The value Default means the value in the preferences is used.
- Unique constraints follow db unique constraints When set to true
(Default), all unique constraints in entities have to have a unique
constraint in the new relational model data after refresh, or they'll be
removed. When set to true, new unique constraints are created from newly
found unique constraints. When set to false, unique constraints without
a unique constraint in the new relational model data are left as-is and
there aren't any new unique constraints created from unique constraints
in the new relational model data. The value Default means the
value in the preferences is used.
- Update custom properties after refresh When set to true, any
custom property in an entity, entity field, typed view, typed view field
or stored procedure will be updated with a similar named custom property
in the newly catalog information, after a refresh of the catalog(s).
Setting this option to true can break your own code, so use this option
with care. If you have set Retrieve db custom properties to false, this
option has no effect. The value Default means the value in the
preferences is used.
Conventions: Model First Development
Designer behavior
- Reflect nullability of element field in target field. Boolean
property which makes (when true) the designer change the nullable flag
on a target field based on the IsOptional value of the model field.
Default is false.
- Sync relational model data element name after rename When set to
true, the designer will automatically synchronize a table name or table
field name with its mapped project element if the project element is
manually renamed in the designer. Default is false. The value Default means the value in the
preferences is used.
Relational model data element construction
- Insert underscore at word break case insensitive dbs. Similar to the
Case Sensitive variant, but is now used for case insensitive databases.
- Insert underscore at word break case sensitive dbs When a new table
or table field has to be constructed based on a project element (entity,
field, typed view), or when the project element is manually renamed and
Sync relational model data element name after rename is set to true, the name
for the element is based on the project element name using this setting.
Ignored on case-insensitive databases. When set to true, an underscore
is inserted at word breaks. Default is false.
- Prefer decimal over currency types When set to true (default),
the designer will, when creating a relational model data field element,
prefer the decimal type (if present / supported) over currency / money
types (if present / supported), when more than one database type matches
the model element's .NET type.. When set to false, currency / money
types are prefered.
- Prefer natural character types When set to true (default), the
designer will, when creating a relational model data field element,
prefer natural character database types (e.g. nvarchar, nchar) over
normal character database types (e.g. char, varchar), when more than one
database type matches the model element's .NET type.. When set to false,
normal character database types are prefered. A new project will inherit
this value
- Prefer variable length types When set to true (default), the
designer will, when creating a relational model data field element,
prefer variable length database types (e.g. varchar, varbinary) over
fixed length database types (e.g. char, binary), when more than one
database type matches the model element's .NET type. When set to false,
fixed length database types are prefered.
- Relational model data element name casing case insensitive dbs.
Similar to the Case Sensitive variant, but is now used for case
insensitive databases.
- Relational model data element name casing case sensitive dbs When a
new table or table field has to be constructed based on a project
element (entity, field, typed view), or when the project element is
manually renamed and Sync relational model data element name after rename is
set to true, the name for the element is based on the project element
name using this setting. Ignored on case-insensitive databases.
AllUpperCase means all characters are upper-cased. AllLowerCase means
all characters are lower-cased, AsProjectElement will use the name of
the project element as-is.
- Sequence pattern The pattern which is used to construct the
names for sequence objects in the relational model data using
auto-mapping functionality. Pattern elements can be: {$EntityName} for
the name of the entity containing the identifying field which is
sequenced and {$FieldName} for the name of the field which is sequenced.
You can also specify any literal text. An element can be mentioned more
than once.
- Set schema name after group name. If true (default), an
automatically created table will have its schema name set after the
group name the entity is in. Otherwise the schema name will be set to
the default schema name.
Conventions: Target Framework Settings
This group shows the settings related to the target framework chosen,
e.g. the settings related to the LLBLGen Pro runtime framework are located
here. See for the framework specific settings the LLBLGen Pro manual for the
specific target framework shipped with LLBLGen Pro
Conventions: Code Generation, General
Task performers, General
- Clean up vsnet projects When set to true, the VS.NET project
file task performer will first remove all references to files which were
generated by LLBLGen Pro from an existing VS.NET project file, before
adding the files generated. Default is true. A new project will inherit
this value
- Connection string key name pattern The pattern for the key in the
generated config file under which the connection string for a target
database is stored. A macro is required for this property: {$ProviderName}.
This macro is replaced with the short name in the driver.config of the
active driver. This way multiple connection strings can be emitted into
the generated code without name clashes.
- Encoding to use The encoding to use for text files being
written by the generator task performers. Use UTF8 if you use Visual
SourceSafe, as Visual SourceSafe can't handle unicoded textfiles
- Fail code generation on write error When set to true (default is
false), the code generator engines of LLBLGen Pro will throw a
GeneratorAbortException to terminate the code generation cycle if a
write error occurs. A write error is generated when the target file
exists and is readonly and failwhenexistent is false for the executing
task
- Root namespace The initial root namespace to use for code
generation
- Store time last generated into project When set to true (default:
false), the time the last generation cycle for a project took place is
stored inside the project. This will make the project 'changed' after
every generation cycle, which could influence sourcecontrol behavior if
you store the .lgp file in a sourcecontrol system. A new project will
inherit this value
Conventions: Code Generation, Attributes / Additional Interfaces /
Additional Namespaces
The groups Attributes, Additional Interfaces and Additional
Namespaces, allow you to specify the
defaults for Additional Attributes, Additional Interfaces and Additional
Namespaces resp. for the various element types found in the project. These
defaults are then inherited by every instance of these types (for
attributes, if a rule is applied, the attribute is only inherited if the
rule resolves to true for the particular element). At the
element level you can decide (by editing the element in its own editor,
on the Code gen. info tab of that element's editor) whether you want to
inherit the default, ignore it for that element, or add new definitions only
for that element.
This allows you for example to specify in the Project Settings the attribute definition 'Serializable' for the element type
'Entity', which is then inherited by every entity definition in the
project. If you don't want this attribute definition to be specified on a
particular entity, you can open that entity's editor, go to the Code gen.
info tab and uncheck the checkbox for the inherited 'Serializable'
attribute, or define a rule which resolves to true only for a subset of all
entity definitions in the project. When code is generated for the project, every class representing
an entity definition which inherited the attribute will then have the 'Serializable' attribute applied to
it. See for more information:
How to assign attribute
definitions to elements easily.
Conventions: Type Shortcuts
This group allows you to define additional type shortcuts which are used
for specifying field types in the editors for entities, value types, typed
views and stored procedure calls. Shortcuts make it easier to specify a
type. LLBLGen Pro already defines a list of shortcuts for all types
supported by all supported databases, which are called the System Type
Shortcuts. System type shortcuts are readonly and can't be removed.
Additionally it will auto-create custom type shortcuts for
imported types, like enums, and the types supported by loaded type
converters, as well as, the CLR UDT types retrieved from a SQL Server
database, when working database first.
To add a new custom type shortcut, simply add a new line in the grid on
the Custom Type Shortcuts tab and press enter.
Conventions: Type Conversions
To overcome .NET type mismatches between the model element and the mapped
target element, the LLBLGen Pro designer supports Type converters.
Type converters are classes which can convert from one .NET type to another
and vice versa. Type Converters are supported on the LLBLGen Pro runtime
framework and NHibernate (for NHibernate, the TypeConverter type has to
implement the NHibernate specific interface IUserType). There are two kinds
of type converters: normal type converters and
system type converters.
To set a type converter for a field, you do so on a
Field Mappings Tab of the
containing element's editor. This can be a time consuming process if your
project has a lot of fields which require a type converter. To overcome
this, the designer supports Type Conversion Definitions. These type
conversion definitions define for a given .NET type pair and optionally a
set of filters, a type converter. If the designer recognizes this .NET type
pair and optionally filters match too, and additionally the
Project Settings setting Auto assign type converter to field mapping is set to true, the type converter
of the defined Type Conversion Definition is assigned to the model field
automatically. This happens when you refresh the relational model data or
when you map an entity onto a target element.
Type Conversion Definitions are stored per database, as different target
databases can require different type converters or different filters (as the
filters are target database specific). To edit type conversions for a given
project, right-click the project node in
Project Explorer and select Edit Type Conversion Definitions...
or select Project -> Edit Type Conversion Definitions... from the
main menu.
The Type Conversion Definition editor edits the type conversions per
database. Only databases which currently have a Relational Model Data
storage in the project are selectable.
In the Defined type conversion definitions list, the currently
defined type conversion definitions are shown with the filters, types and
type converters they are based on. To remove a type conversion definition,
select it in the grid and click Remove selected. To add a new type
conversion definition, click the Add new... button. This will open a
dialog which is described more in detail below.
Adding a new Type Conversion Definition
When you click the Add new... button, a dialog is opened which
allows you to define the base elements for a type conversion definition. You
start by selecting the Relational Model data .NET type. This is the .NET
type related to the database type of the table/view field. This type is
called the from type. Based on this .NET type, the list of
Type converters to select from in the Converter to use combo box is
filtered. After you've selected a type converter in the Converter to use
combo box, the Model .NET type is known, as that's the core type of
the type converter. Click the OK button to create the Type Conversion
Definition, which will be a conversion definition between the Relational
Model Data .NET type and the Model .NET type using the Converter to use
type converter.
Additional Filters
Per type conversion definition you can specify extra filters. This can be
useful when more than one database type results in the same .NET type, or
you want to filter on length for example. To enable a filter, check the
checkbox in front of a filter element at the bottom in the Additional
filters on database field properties area. If a filter is enabled, it
has to match exactly with the target field's specific property, e.g. length
or precision to get the type converter of the particular type conversion
definition assigned to the field mapping.
Custom Properties
Custom properties are name-value pairs (name and value are both strings)
which can be used in templates to generate project specific information.
They can be used to drive custom-made templates, be used as additional
output in templates. They don't have a logical function inside the designer.
The templates shipped with LLBLGen Pro emit the custom property value pairs
in XML DOC fragments into the code, so you can use them to add additional
documentation to the various elements. Besides the Project, all major
project elements, like entity definitions, value type definitions etc. allow
the user to specify additional custom property value pairs. When reverse
engineering entities and other elements from the meta-data, LLBLGen Pro
will, if available, add the description / additional properties read from
the relational model data as custom property value pairs.
The Custom Properties Tab allows you to specify the value pairs for the
project itself.